Learned models: the calibration view¶
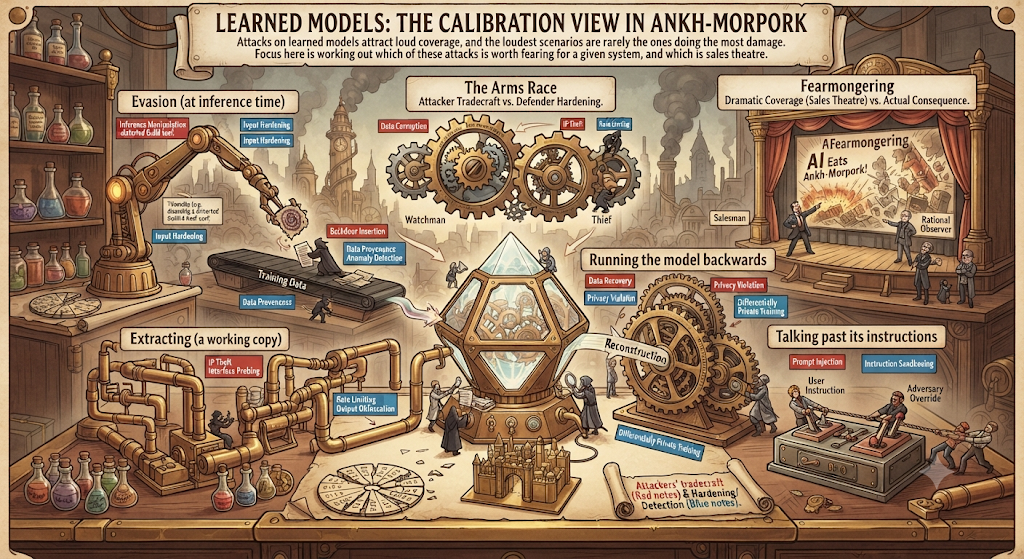
Attacks on learned models attract loud coverage, and the loudest scenarios are rarely the ones doing the most damage. The five mechanics, evasion at inference time, poisoning the training data, extracting a working copy through the query interface, running the model backwards to recover what it learned, and talking past its instructions, are documented in learned models. A defender’s view of AI placed inside security operations can be found in Threat analysis of AI in security operations.
Focus here is working out which of these attacks is worth fearing for a given system, and which is sales theatre. The arms-race framing and the note on fearmongering are the calibration, making starting from consequence rather than from the dramatic version possible.
Last updated: 3 July 2026